The Brain as a Reinforcement Learning Algorithm
(This article tries to make concepts from machine learning digestible to non-technical readers. I try to keep things non-technical.)
I am continually amazed by how often I find analogies between my work as an AI researcher, and my own thoughts. When working on an AI algorithm, nothing is a more promising sign than the realization that my own brain has the same behavior as the algorithm I am developing.
This is especially true when the behavior is irrational. If both the brain and an AI make the same types of mistakes, it is a valuable learning experience, and it is also a sign that you are on the right track.
I would like to share some of my discoveries with others. They have helped me immensely with introspection and meditation of all kinds, and I hope they will be of use to other people as well.
I am currently working on a machine learning model that extends Deep Q-Networks (DQN), an algorithm invented by Deepmind. I will try to explain this model in terms that are understandable to lay people. Hopefully this can help other people understand their own minds better, just like it did for me. I will give concrete examples of useful mind hacks based on this model later in this article.
It's important to point out a common aphorism from statistics first: "All models are wrong, but some are useful". In other words: What I describe here is almost certainly not how the brain actually works in reality. However, the behaviors predicted by this model are very often eerily close to the behaviors shown by people in real life. This makes it useful in practice. It is also possible that I am subject to confirmation bias here. One thing is certain though: Thinking about this has helped me greatly with introspection, and some of the mind-hacks I derived from it are the most effective productivity increasing tools I have found so far, and beat any techniques I have read about in self-help books.
A model of the brain
My reinforcement-learning model can be decomposed into the following components:
-
Memory
There is an internal memory storage for factual information. This is for memories in the traditional sense, i.e. facts of information.
Examples: "My name is Florian.", "One plus one is two.", "The mitochondria is the powerhouse of the cell."
We can in principle store an arbitrary amount of information as memories, although in practice we will have difficulties recalling all of it because our brain is not perfect at storing and recalling data.
-
State of Mind
A subset of our memory is a currently active "state of mind". This information is not about facts. Instead, it is abstract information whose only purpose is to influence the decisions we make. Our state of mind can be informed by memories, but is ultimately distinct from it.
Examples: The feeling of an emotion, the act of brainstorming about a topic, the attempt to recall a distant memory
Our state of mind has a limited size. We can't easily feel multiple emotions at the same time, or concentrate on multiple topics at the same time, without becoming overwhelmed and losing track of our trains of thought.
-
Thoughts
There are specialized algorithms that transform data. This can depend on both our memories and our state of mind, and can also alter both of them.
Example where factual memory alters factual memory: "Because three is larger than two, and two is larger than one, I can infer that three is larger than one."
Example where factual memory alters state of mind: "Because I noticed a fact that surprised me, I am now brainstorming about that topic."
Example where state of mind alters factual memory: "Because I am brainstorming about a topic, I am comparing memories related to this topic to each other."
-
Decisions
Decisions are made by a variant of a Deep Q-Network (DQN).
The network looks at the current situation we find ourselves in, and decides what actions we should take next.
For each possible action, the DQN predicts an estimate of how good of an idea this is. We then perform the action that received the best rating.
However, we make some modifications to the way DQN's normally work:
- The current situation consists not just of what our senses report, but also includes our own state of mind.
- The actions the DQN can choose between are not just physical actions in the environment, but also thoughts, which are internal to ourselves and alter our state of mind, as well as memories.
As a consequence, the DQN can decide that we should think about a topic in more detail before taking action.
The following image illustrates how this model works:
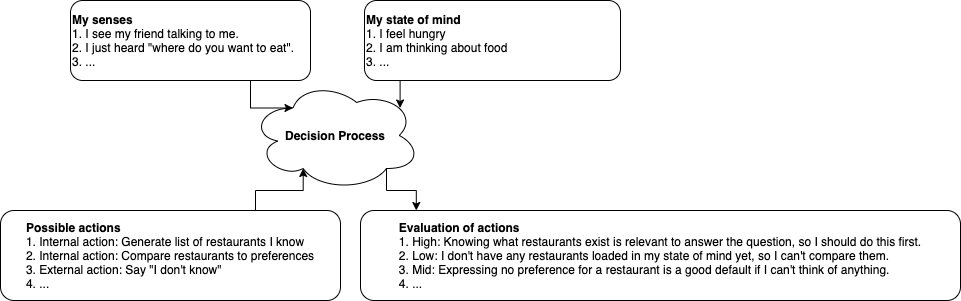
Note that this image shows only the first step: You are asked where you want to eat. Since you are not currently thinking about restaurants (they are not part of your state of mind), the first action you pick is to start thinking about restaurants. This is an internal action that loads memory data about restaurants you know into your state of mind. After this, you think about the question again (not shown in the image). Since you now have restaurant data in your state of mind, the evaluation will be different, and you will pick action 2: "Compare restaurants to preferences." This is again an internal action, which will update your state of mind. After that, you will have all relevant information loaded in your state of mind to make a decision, so the next action will be telling your friend where you would like to eat. If you discover no preference, you will default to "I don't know".
As you can see, even a simple question like "where do you want to eat" requires several steps to answer, and interactions between every part of the model.
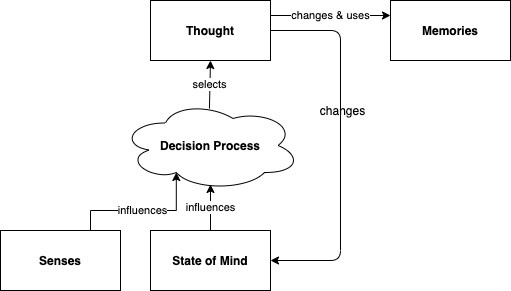
I believe that much of the complexity of the human brain stems from the interaction between individual thoughts that can alter internal states of mind, and the decision process that decides which thoughts to have based on the current state of mind. This can result in complex processes where each thought you have determines what your next thought should be about. In other words, this model describes how humans can have trains of thought.
This image shows the loop that occurs when you think about something:
Learning
The most important question when developing machine learning models is how the system can be trained. Given that the model described here has so many complex interactions, how can it learn?
Immediate learning
The ultimate reward signal comes from biologically hardcoded signals (dopamine, serotonin).
When you take the action "bite into a steak", your pleasure receptors activate and the decision process learns that its choice of action was a good one. Likewise, if you feel pain then it learns that it chose poorly, and will avoid this action in similar situations in the future.
In addition to this, the decision process also uses temporal-difference learning, just as a DQN does. This concept is quite simple: In the absence of a reward signal for an action, simply use the expected reward of your own next action as the reward signal for the previous action.
To give an example: Eating something nice gives an immediate reward signal. Your decision process now has an estimate of "high reward" for the action of eating something nice. The action "go to a nice restaurant" does not have an immediate reward signal. However, the action "eat something nice" comes right after it, and has a high expected reward. Therefore the action "go to a nice restaurant" receives a high reward from the anticipation of the next action.
Each action is rewarded by the anticipated reward of the action that comes after it. In this way, the expectation of rewards propagates through time, and through you plans of actions, so that every action has an expected reward, even though only a few of them actually trigger a biological reward signal.
It is important to note that the decision process does not know which parts of its inputs (senses and state of mind) are responsible for which parts of its predictions (the expected rewards of each action).
This means that when the decision process receives a reward or a punishment for an action, it will associate that reward or punishment with all current senses and active states of mind.
Let's say you listen to a specific song during lunch. The song is part of your state of mind, so you brain will associate listening to the song to the good feeling you get when you eat something tasty. If you also listen to this song at many other times when you are not eating lunch, then your brain will realize that this association was random, and nothing much will happen. But if you always listen to the same song during lunch and not at other times, then your brain will associate the song with an increase in the expected reward of all actions that have to do with lunch. In other words, you will get hungry when you hear the song.
This matches nicely to both classical and operant conditioning.
Attention and availability
The decision process can't actually make an estimate of the reward for every possible action. After all, the number of possible actions is effectively infinite.
Instead, there are a number of candidate actions that are considered at any given point in time. Some internal actions (thoughts) can replace candidates. This means that only a limited number of actions are at the top of your mind at any given time. It takes introspection in order to realize that other actions are even possible, and to consider them as candidates.
A person who is good at generating unusual candidate actions that receive a high estimate is called creative.
A person who quickly generates a strong set of previously proven candidate actions is called experienced.
Abstract learning
The DQN tries to reduce uncertainty in its predictions. A reduction in uncertainty in the reward signals will itself generate a reward. Since the state of mind influences the DQN's estimates, and thoughts influence the state of mind, this means that even abstract thoughts can affect the uncertainty of predictions, and receive feedback in this way.
This reduction of uncertainty is a third source of reward signals for our decision process, in addition to the biological reward signals, and the temporal difference learning.
In our example, the first selected action was "Generate list of restaurants I know". Why is this the case?
The brain has learned from previous experience that "Generate list of restaurants I know" will update our state of mind in such a way that we can be more confident about our expected rewards. After all, we are more likely to choose a good restaurant if we actually spend time thinking about our options.
This reduction of uncertainty is rewarded, and so we learn to use "Generate list of restaurants I know" in the future whenever we want to make a decision about food.
The drive to reduce uncertainty about our expected rewards is very powerful and explains a great deal about our motivations:
- It causes us to consider as many possible options as possible for dealing with a problem. This helps us to make better decisions in practically every field of everyday life.
- Brain teasers and puzzles are fun to solve, because they are all about finding new ways to reduce uncertainty.
- The drive to reduce uncertainty is only powerful when there is a final reward, that is not itself based on uncertainty, which we try to optimize. Different people have these expectations of final rewards calibrated differently. Some are only interested in actions with concrete rewards in a very short amount of time. These people are action-oriented, but tend to overlook more complex ideas. Other people take such a long and abstract perspective that they are motivated to work on purely theoretical problems. Such people often become mathematicians. It is no coincidence that mathematicians are often considered detached from reality: That is what happens when the drive to reduce uncertainty becomes so strong that it forms a feedback loop with itself, so that external rewards no longer matter.
Mind hacks
I have found that this model is useful for understanding my own psyche in a multitude of ways, but there are two concrete mind hacks I have discovered that work particularly well for me.
Motivation transfer
This is a technique for transfering motivation from one action to another.
You can use it to increase your motivation to perform some desirable action, while at the same time decreasing the distraction by some undesirable other action.
It works like this: Pick a thought A you want to have more, and a thought B you want to have less. Make up a bridge X that connects A to B. This must be a clear and immediate association in the brain that connects A to B both temporally and causally, so that A triggers B. Force yourself to make association X for a couple of days or weeks whenever you are thinking about B. As a result, A will sap some of the reward of B, which weakens B and strengthens A.
Note that both A and B can be either physical actions or thoughts.
Why does this work? The intuition is that you convince yourself that the reason that B is pleasurable is actually A.
Example: A is “doing sports”, B is “eating fastfood”, X is “The reason this food tastes so good is because I have done sports.”
You may note that X does not actually make sense in this example. The association X does not have to be logical. You are not trying to win a debate, you are trying to hack your own mind. It's more important that you can keep X in your mind and believe it is true, than that it is actually true. I find it easy to convince myself that doing sports makes food taste better, and so the technique works for me even though it makes no logical sense.
Using this technique causes me to do more sports, while simultaneously lowering my desire to eat fast food on days when I haven't done enough sports.
Note that this technique does have a negative side-effect as well: It will cause you to want B more whenever you are doing A. This is a temporary effect though, so you can avoid this negative by making sure that it is difficult to do B right after A. For example, if I do sports only when I am not hungry, there is no risk that I will want to eat fast food afterwards.
Explaining away unwanted associations
This is a technique for explaining away unwanted associations and desires. You can use this to improve your emotional balance, or to decrease the risk of getting distracted by unwanted thoughts.
It works like this: Pick a thought B that you have whenever condition X is met, where B is something you don't want. Make up an additional condition Y that makes thought B actually useful. Repeatedly imagine a situation in which X and Y are true, and having thought B is useful. Also repeatedly imagine a situation in which X is true, Y is false and B is not useful. Your brain will now associate B with the combination of Y and X, not with just X alone.
It's important to note that you are not saying that B is generally bad. This would cause cognitive dissonance, which makes it much harder to convince your brain to learn it. You are just changing conditions and making it more specific. In my experience, it is much easier to redirect an existing association in my brain, than to attempt to extinguish it entirely.
Example: B is “getting aggressive”, X is “being angry”, Y is “you are actually about to physically fight someone”.
Since you are usually not actually about to physically fight anyone, this makes you less likely to get angry, and makes it easier to keep a cool head.
There are many variants of this example that can help you to achieve a better emotional balance.
Conclusion
The model I have outlined here is useful for understanding your own behavior. The model is almost certainly incorrect, like all models are, but it has empirically proven useful to me. I hope that the mindhacks I derived from this will prove useful to other people as well.